Store Hail MT from WES data to DNAX
I used Hail on a Spark cluster to perform QC on WES data, but I did not write the MatrixTable (MT) to DNAX. Below is my code. When I attempted to run mt.write(url), the process took an extremely long time and eventually failed.
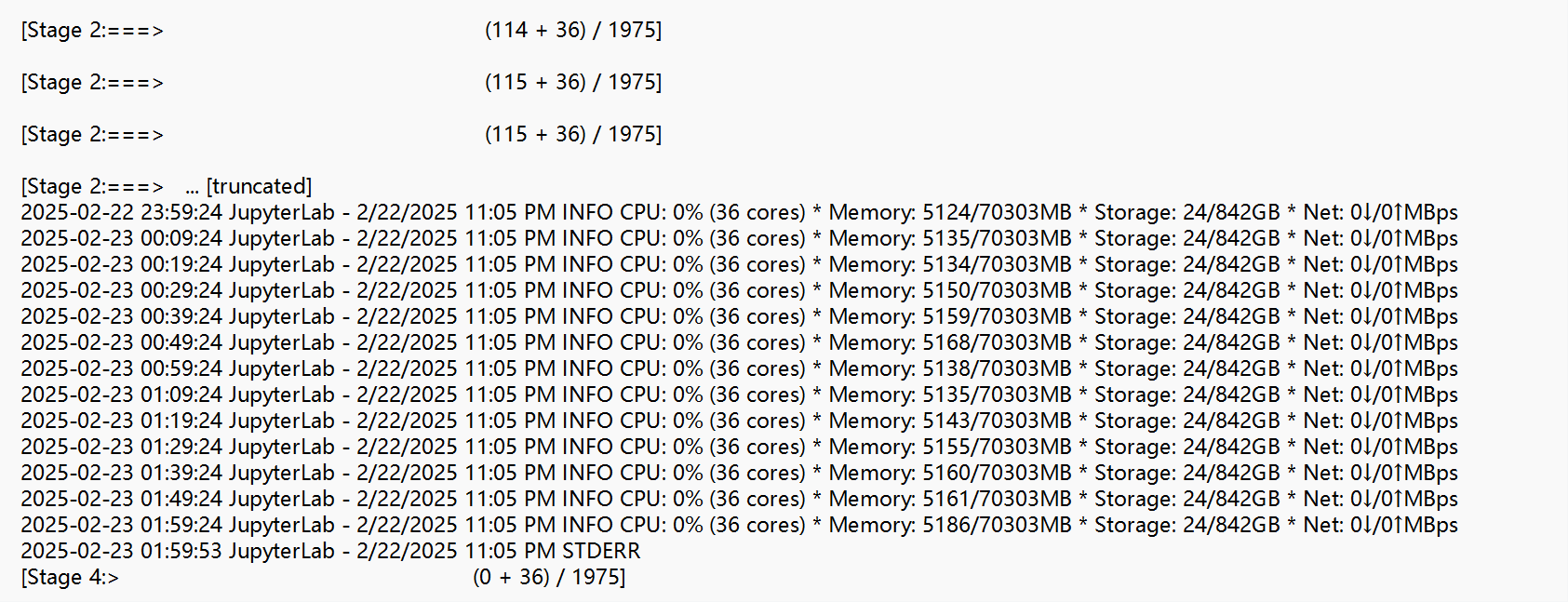
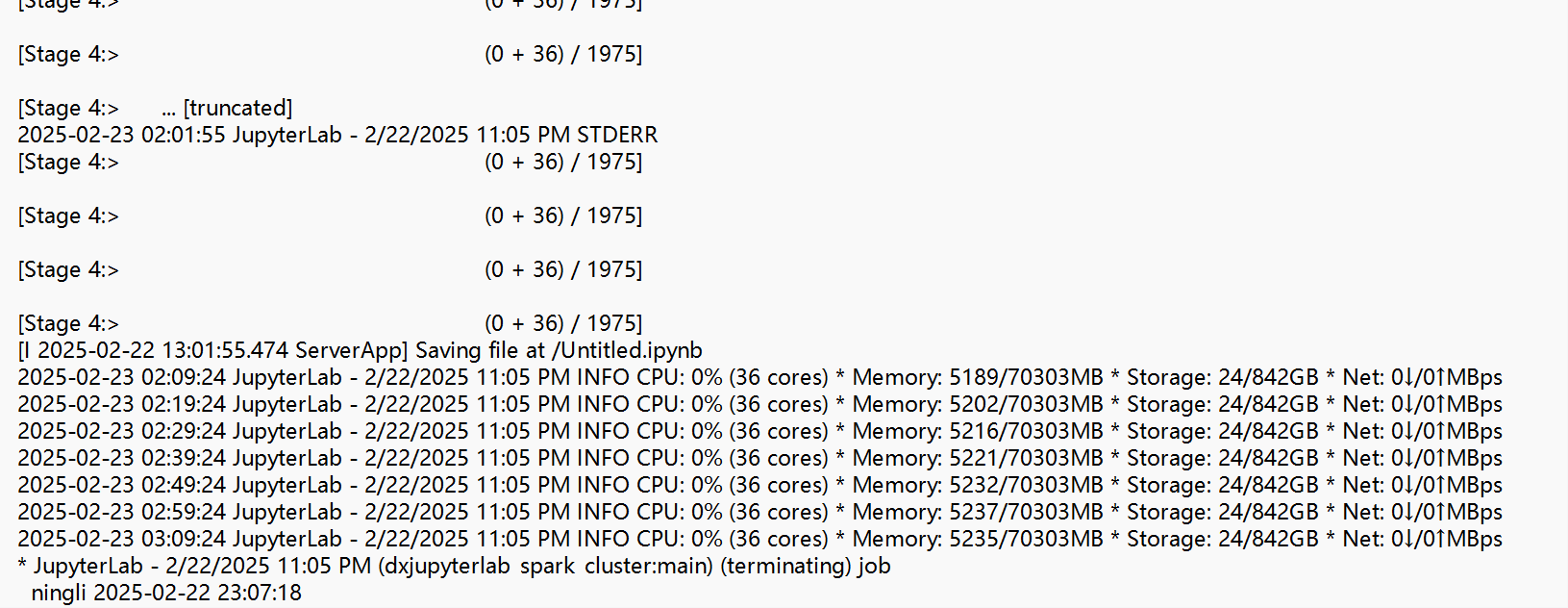
The instance type I used was mem1_ssd1_v2_36, with 2 nodes. The log file showed the following resource usage:
INFO CPU: 0% (36 cores) * Memory: 5235/70303MB * Storage: 24/842GB * Net: 0↓/0↑MBps
It seems that despite the available resources, the writing process was not progressing efficiently. Could you provide any insights or suggestions on how to resolve this issue?
import pyspark
import dxpy
sc = pyspark.SparkContext()
spark = pyspark.sql.SparkSession(sc)
spark.sql("CREATE DATABASE my_database LOCATION 'dnax://'")
import hail as hl
my_database = dxpy.find_one_data_object(
name="my_database",
project=dxpy.find_one_project()["id"]
)["id"]
hl.init(sc=sc, tmp_dir=f'dnax://{my_database}/tmp/')
file_url = 'file:///mnt/project/Bulk/Exome sequences/Population level exome OQFE variants, pVCF format - final release/ukb23157_c21_*.vcf.gz'
mt = hl.import_vcf(file_url,
force_bgz=True,
reference_genome="GRCh38",
array_elements_required=False)
print(f"Num partitions: {mt.n_partitions()}")
mt.describe()
mt_name = "test.mt"
url = f"dnax://{my_database}/{mt_name}"
mt.write(url)
Comments
1 comment
Stuck on this process too… Did you find an efficient way to store the Hail MT?
Please sign in to leave a comment.