500K WGS batch IDs and GRCh38 coordinates
I'm trying to figure out how to query DRAGEN population VCF file batch IDs that correspond to specific genes. For this, I attempted to predict genomic coordinate ranges of the files based on batch IDs. Since each batch spans a 20 kb segment, I suspected that the following below formulas may predict the range of variants in each file:
Start: (20,000×batch_id) + 1 ; inclusive
End: 20,000 × (batch_id+1) ; inclusive
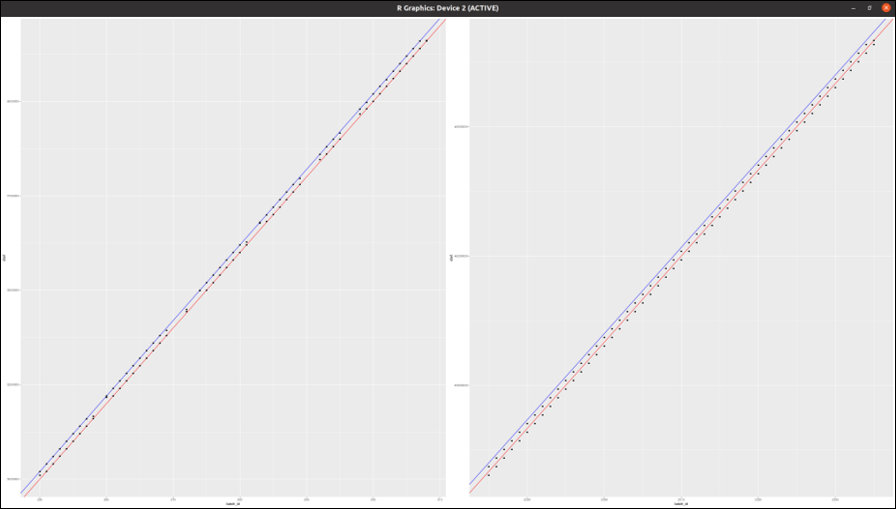
I've tested the above for all batches of chr21. While the initial batches perfectly conform to the above, deviations begin to appear after batch #1729 - please see the attached plots.
Based on my estimates, manually creating a coordinate lookup table for all 150,000 pVCF files across the whole genome would cost ~ £700.
Thanks, Sourena
Comments
5 comments
We have recently released a resource with the coordinates for each pVCF block (Resource 2009, see the Notes tab of https://biobank.ndph.ox.ac.uk/showcase/field.cgi?id=24310)
The ranges of the pVCF blocks are consistent. However some blocks have fewer positions due to low variation/mapping etc
This seems useful but the file names don't match. I downloaded the Resource for field 24310 with
wget -nd biobank.ndph.ox.ac.uk/ukb/ukb/auxdata/dragen_pvcf_coordinates.zip
The first entries look like this:
ukb24310_c1_b0_v1.vcf.gz,chr1,10061
ukb24310_c1_b1_v1.vcf.gz,chr1,20019
ukb24310_c1_b10_v1.vcf.gz,chr1,200001
ukb24310_c1_b100_v1.vcf.gz,chr1,2000001
ukb24310_c1_b1000_v1.vcf.gz,chr1,20000004
ukb24310_c1_b10000_v1.vcf.gz,chr1,199995141
Which seems like just what I need. But if I go to the folder "Whole genome GraphTyper joint call pVCF" it has similar files but with names like:
ukb23352_c7_b3106_v1.vcf.gz.tbi
I can't find the Dragen files?
Where do I find the files with the ukb24310_ names? Alternatively, where can I get an index for the ukb23352_ files? Or for the files in "Whole genome variant call files (VCFs)" which I really don't understand at all and are not even grouped by chromosome?
Thanks.
The ukb24310 files should be in folder Bulk > DRAGEN WGS > DRAGEN Population level WGS > chr N
If they are not present, it could be because the third set of data needs to be dispensed.
Sorry, ignore that last comment, the pVCF files are in the second set, see https://www.ukbiobank.ac.uk/media/dovbae03/uk-biobank-final-whole-genome-sequencing-release-faqs_v1-0.pdf .
Thanks. This issue is being handled on the other thread https://community.ukbiobank.ac.uk/hc/en-gb/community/posts/17782930848029-Which-RAP-tools-work-natively-with-the-segmentation-of-the-genome-into-tiny-chunks-with-no-index
Please sign in to leave a comment.